
【產業剖析】探討 DeepSeek 出世將如何改變 AI 產業
DeepSeek 為一間中國量化對沖基金公司「幻化魔方」底下的 AI 新創公司,成立於 2023 年,今年一月底,DeepSeek 推出了其開源推理模型 DeepSeek-R1 及論文,一度造成美國股市恐慌性拋售 AI 公司,Nvidia、Broadcom、TSM 等皆遭到下殺。

重點整理:
1.DeepSeek 模型的推出:DeepSeek-R1 模型的推出,大幅降低了踏入 AI 競爭的門檻,未來僅需依靠蒸餾技術,中小企業、甚至家戶即可自行創建、微調自己的推論 AI 模型。
2.對 AI 產業的影響:這一次 DeepSeek 的爆發,象徵 AI 推理成本大幅度的下降,將加快 AI 從實驗室走向家戶的階段,真正將技術實行在終端上,因此並非以 AI 泡沫作為解讀,反而此次促成 AI 不同於 2000 的網路泡沫,因無法落地使用而最終走向失敗。
3.對市場未來的方向: 對 AI 硬體持中立態度,未來訓練更高級,先進模型仍需運用比現今更大的算力需求,因此不宜保持過度悲觀,而 AI 軟體、邊緣 AI、PC、手機等為此波最大受惠者,加速將 AI 帶入到以上終端產品,增家公司競爭能力。
前言
在 2 月份投資專欄中,我們有簡單介紹 DeepSeek 公司背景以及競爭格局可能的改變,本篇將再更深入針對 DeepSeek 所推出的 AI 模型以及其將如何影響 AI 產業進行探討。
有關過去針對 DeepSeek 事件介紹及機構觀點,可參考下面文章,將有更詳細的解讀:

DeepSeek 推出 R1 模型引發全球轟動:
在過去 ChatGPT 發布 o1 模型前,市面上尚未有其他相關大型公司擁有其強大推理之同等模型,然而在 1 月,DeepSeek 發布了 R1 具備推理能力聊天機器人,其宣稱以更低的成本卻達到與 o1 相同同樣等級的效能,並且開源公布了其所使用的訓練方法,以及多個蒸餾*的小型模型,雖然蒸餾的模型不具備推理能力,然而其在多個數學、程式等解答問題能力上仍領先 GPT-4o 並且接近於 o1-mini。
*模型蒸餾 ( model distillation ) : 讓規模較小,結構簡單的 AI 模型直接從大型、複雜的 AI 模型學習,比起重頭訓練更省成本,且可以安裝在較簡易的設備如手機、PC 上。
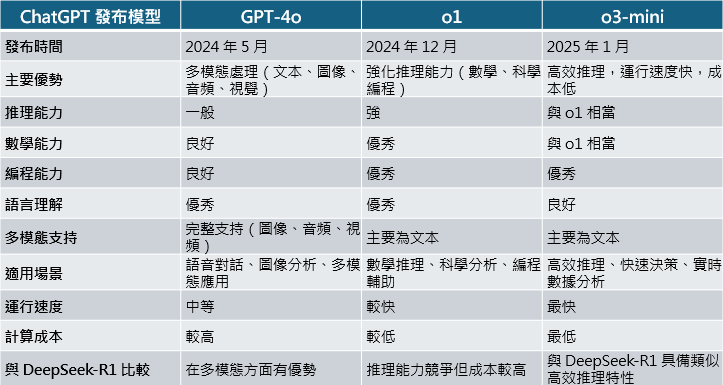
DeepSeek R1 模型的成功之處
其實在模型的推理方面,其 DeepSeek R1 模型能力競爭上與 ChatGPT o1 相近,然而過去數年以來,ChatGPT 以及各大業者幾乎皆以閉源形式進行 AI 模型的開發,這樣的模式雖然有助於保持公司競爭力,防止其技術短時間內被同業對手追上,然而也開啟了過去兩年來美國大型 CSP 業者 (Meta、Google) 的算力戰爭儲備競賽,各大業者採購了大量 Nvidia 的 GPU 晶片及自研 ASIC 晶片、建置資料中心,彼此都投入了鉅額成本在模型開發上。
在談 DeepSeek 創新之處前,必須先介紹訓練 AI 過程中的獎勵機制與方法,在語言模型(如 ChatGPT)中,強化學習主要透過 SFT、RLHF(Reinforcement Learning with Human Feedback,強化學習與人類回饋) 來提升模型的回答質量,主要步驟如下:
- 先進行監督式微調 ( Supervised Fined-Tuning,SFT ),可以理解為先標記好答案,讓 AI 模型在訓練過程中可以一邊對比誤差,一邊給出更優質的答案
- 利用 RLHF 進行微調:
a. 人類標註者評價模型輸出,給出品質較好的答案更高分。
b. 比較不同答案的優劣,幫助模型學習什麼是「較好的回答」。
c. 使用強化學習,讓模型偏向選擇較高獎勵的答案,提高回答的品質。
- 最終效果:模型能夠學習更符合人類語言習慣的回答方式,提高可讀性、邏輯性與推理能力。
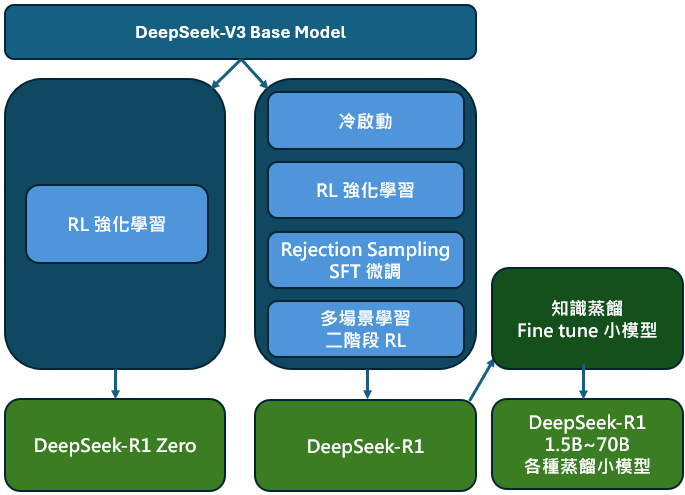
而此次 DeepSeek 發布的論文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》中,其分別開發了 DeepSeek-R1-Zero 以及 DeepSeek-R1-Zero 模型,其中 R1-Zero 的創新在於其省略了傳統 LLM model 訓練的第一個步驟 (SFT) 通過,讓模型無需借助外部數據,僅依靠其自身的推理能力,即可隨時間自我進化發展出解決問題的能力,實現從內部的自我的提升。模型出現了開始出現複雜行為,如反思 ( 回顧並重新評估之前步驟 )、探索其他問題的解法等行為,甚至如人類一樣,會思考問題時會經歷「頓悟時刻 (aha moment)」,學會為問題分配更多的思考時間。
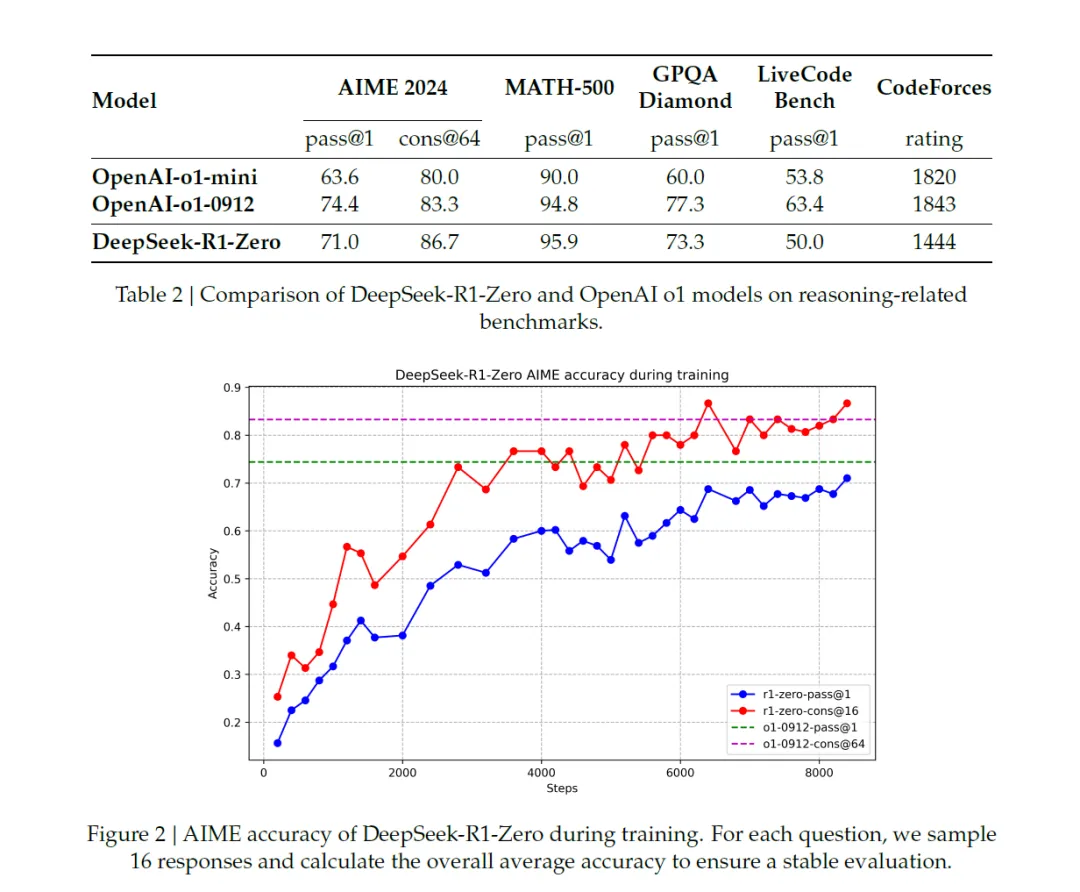
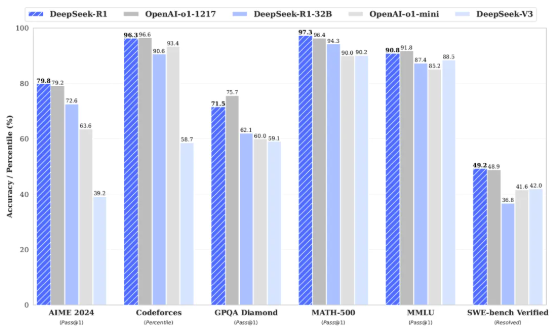
圖中提到 DeepSeek-R1-Zero 模型展現強大的數學、程式能力,然而其問題在 DeepSeek-R1-Zero 的可讀性、語言表達能力等相較 o1 等模型仍然較差,因此 DeepSeek 加入冷啟動 (Cold Start)、也就是先準備一堆思考鍊 Chain-of Thought,CoT 範本讓他學習,之後同樣通過 RL 學習強化,之後 Rejection Sampling 拒絕品質較低的回覆以及 SFT 的微調,成功開發出 DeepSeek-R1 模型,並且重點之處在於,DeepSeek 通過蒸餾模型,微調出較小但同樣具備推理能力的模型,這些模型的參數從 15 億到 700 億不等,其中最小的 DeepSeek-R1-Distill-Qwen-1.5B 甚至在 iphone 16 即可運行,而中等的 DeepSeek-R1-Distill-Qwen-32B 模型能力則媲美 o1-mini 模型,顯示相較於投入大量成本使用 RL 訓練 AI 模型,中小企業、甚至家戶僅需透過蒸餾模型技術,即可達到接近於先進 AI 模型的程度,大幅降低了踏入 AI 應用的門檻。
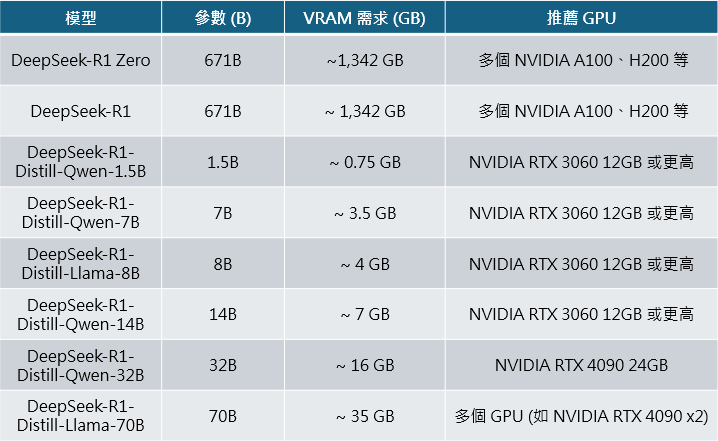
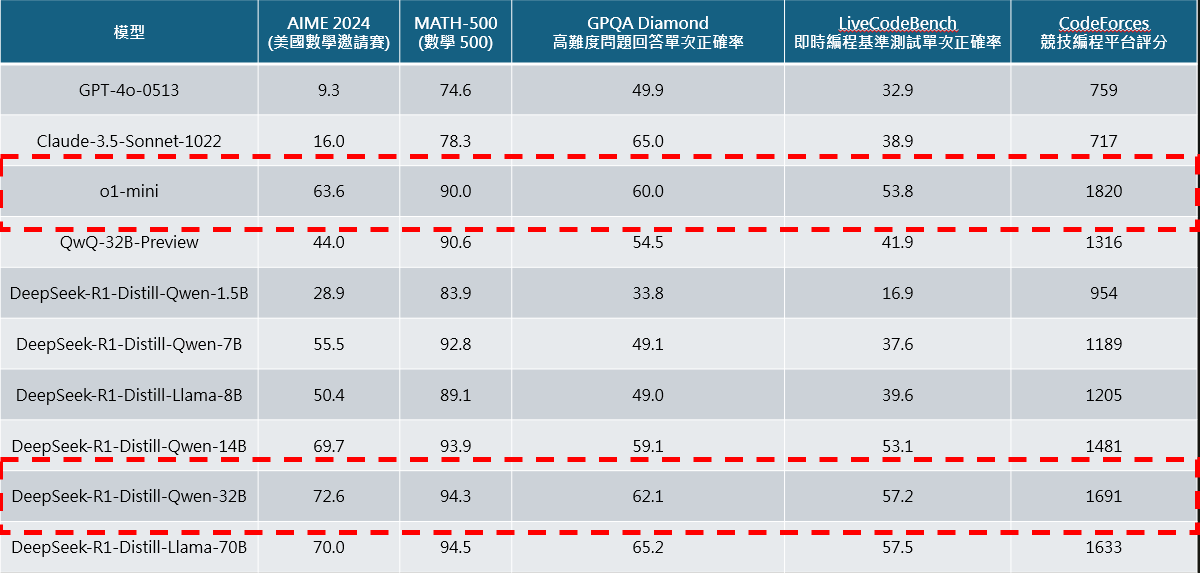
DeepSeek R1 模型對 AI 產業的影響
- 推理模型將變得更為普遍:在發布模型前,僅有 Google、OpenAI 有能力發布出推理 (Reasoning) 模型,剩下美、中企業仍停在一般的語言生成模型,然而在 DeepSeek 發布以後,許多企業都可以複製 DeepSeek 的訓練方法,將自家模型升級成推理模型,可解讀為中小型的雲端企業與大型雲端公司拉近了距離,同時由於競爭者增加,將引發 AI 推論的價格戰開打,可看到近期 OpenAI 立即發布了最新的 o3-mini 作為回應,並且將其設為免費使用 (但限制問答次數),Google 亦相繼推出更新 Gemini 2.0 Pro,同樣開放免費額度,變相等同於降低整體模型價格,預計未來網頁上的 AI 模型會更加百花齊放並且單價持續下降。
- DeepSeek 的出現引發了市場對 AI 基礎設施需求的擔憂:透過優化演算法,企業可以用更少的 GPU 資源便可發展更高性能的 AI 模型,是否未來對於輝達的 GPU 需求量就會減少,影響未來對於 AI 晶片的需求量? 此正確答案需經過時間的考驗證明,然而持反對論點如 Microsoft 執行長 (Satya Nadella) 多引用 「Jevon's Parodox」作為回應,認為反而會因為門檻的下降,更多人參與市場,反而會讓未來對於 AI 晶片的需求提升,然而觀察 2/5 Google 財報顯示對 AI 資本支出加碼高於市場預期,隔日下跌市場反應來看,投資人的擔憂確實反映在股價上。
*Jevon's Parodox 由 William Stanley Jevons 在 1865 年提出。 這個悖論指出,當某項資源的使用效率提高時,反而會導致對該資源的需求增加,著名的例子是蒸汽機改良後技術升級,運用更少的煤炭,生產出更多動力,當時有人擔心因此煤炭需求降低,然而實際情形是對煤炭的需求反而大增。
長線來看,大型雲端業者仍有投入高額資本支出必要:DeepSeek 的 R1-zero 及 R1 模型是通過 DeepSeek 過去發布的 V3 Base model 通過 RL 強化訓練得出,OpenAI 的 o1 model 也類似,是基於 GPT-4 Base model 訓練後得出,而未來也必須要發展至更高階 Base model 模型 ( 如 GPT 5 ),才能再透過訓練流程得出性能更佳的 AI model,而每一代的 Base model 的發展就必須運用到相較上一代更高的算力消耗,因此亦回應第一及第二點,對於大型 CSP 業者立場而言,他們與中小企業距離相近,然而身為龍頭公司,擁有必須是最先進 AI 模型的壓力 ( 放棄投資將被逐出長期領賽道 ) ,甚至在 Google 定義上的「通用人工智慧」(artificial general intelligence,AGI) ,人類目前僅在等級 1:初步 (Emerging),離真正實現最高階人工智慧還有很大段的距離,也可看出 Google 加大資本支出的立場,但短期科技公司可能會面臨股東壓力,且市場焦點將逐漸從投資 AI 硬體,轉向如何推出 AI 產品 ( 應用端上的實現 )。
- DeepSeek 的出現並非象徵 AI 的泡沫,而是 AI 真正走向大眾市場:引用 Meta 執行長祖克伯的回應:「 隨著時間的推移,就像每個企業都有一個網站、一個社交形象和一個電子郵件地址一樣,在未來,每個企業也將擁有一個客戶可以與之交互的 AI 代理。 我們的目標是讓每個小企業,最終每個企業,都可以輕鬆地將其所有內容和目錄提取到一個 AI 代理中,從而推動銷售並節省資金。 這一時點正在逐步臨近」,這一次 DeepSeek 的爆發,象徵 AI 推理成本大幅度的下降,大幅加快從實驗室走向家戶的階段,因此並非以 AI 泡沫作為解讀,反而此次促成 AI 不同於 2000 的網路泡沫,因無法落地使用而最終走向失敗。

DeepSeek R1 模型將加速 AI Agent 實現,受惠軟體公司
DeepSeek 事件將加速 AI agent 進程,未來開源環境將減低各公司間資訊落差,增快 AI 開發速度投入於應用端,如客戶關係管理如 Salesforce (CRM)、雲端資安產業 CrowdStrike (CRWD) 等公司長期將受惠於 DeepSeek 帶來的影響,未來將能提供更具成本效益的解決方案。提升市場競爭力,因此在 DeepSeek 公布後 AI 軟體相關概念股當周股價不跌反漲,未來看好 AI agent 在終端應用持續增加, 甚至是利用 AI 軟體的新創公司的崛起。
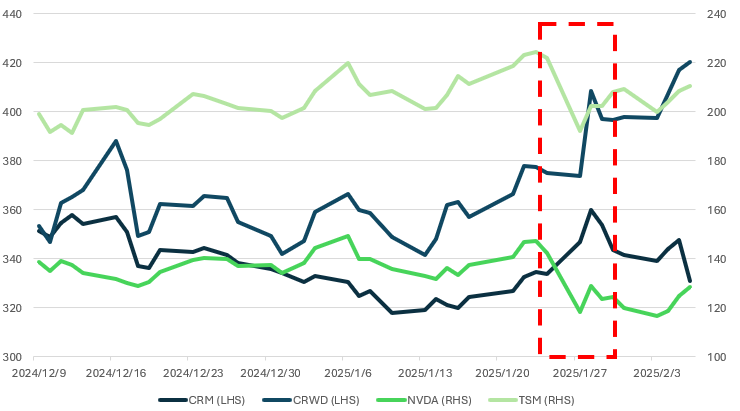
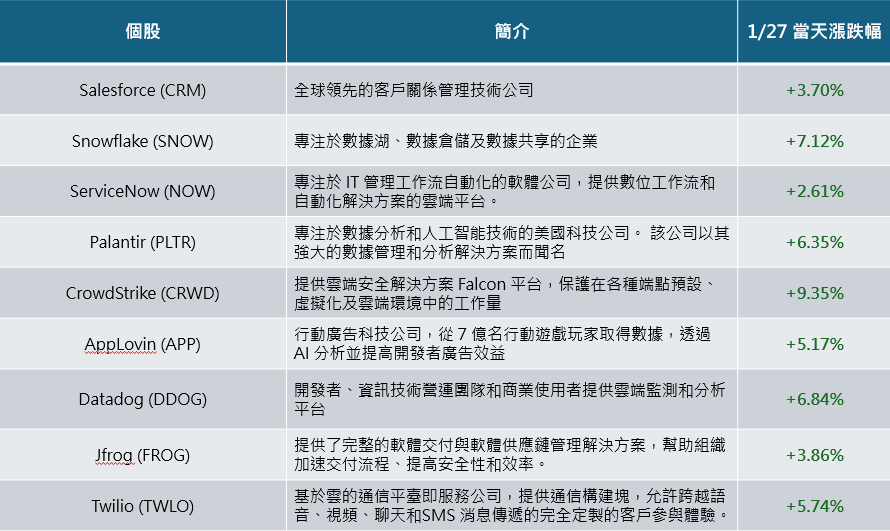
DeepSeek R1 蒸餾模型有望刺激邊緣 AI 應用、手機及 PC 換機潮
DeepSeek R1 所發布之 1.5B ~ 70B 蒸餾模型,讓過去複雜、僅能在雲端上運作的推理模型直接在本地 PC 上運作,大幅增加了 AI PC 未來提升的潛力,過去一年,AI PC 的推動並沒有如預期火熱,主因是尚未看到殺手級應用,除了麥克風、鏡頭增加、具備 Copilot + PC 的 NPU (神經網路處理器(Neural-network Processing Unit)) 具備 AI 算力,和 PC 並沒有太大的差異,人們並沒有因為 AI 而另外購買 PC,PC 的 TAM (Total Accessable Market) 和差異不大。
然而在 DeepSeek 蒸餾模型的推出,加速實現本地端模型推論工作的運行,並結合功能於 PC 上,具備想像空間,然而現階段,AI PC 多數主打的「NPU」( 過去一年由微軟主張,具備 40 TOPs 以上的 NPU 才被稱作 AI PC ),僅能運行 1.5B ~ 7B 的蒸餾小模型,在運行速度、實用程度、評分皆遠不及 o1 模型的水準 ( 詳細比較可回顧圖 5 ),因此推斷,在各家 PC 搶先競爭將須更高算力的 32B~ 70B 下融入本地 PC 下,焦點將從 NPU 轉戰至純 dGPU ( 獨立顯卡,Nvidia 市占 88% ) 或 NPU + dGPU, 在效能大幅提升下,提高客戶的換機意願,實現換機潮,且因 dGPU 成本更高,AI PC 價格將相較於傳統 PC 單價更高,在目前裝有 dGPU 之筆電多數為電競筆電,以台廠的華碩 (ASUS)、微星 (MSI) 等品牌廠經驗相較 Dell、HP 等經驗更為豐富、售後管理經驗、布局相對完善,因此預計美股未來以 Apple 的 mac 系列更為受惠。
結論:DeepSeek 引領 AI 產業突破,未來市場將更注重於 AI 的終端應用
這次的市場波動主要來自於:
1. AI 踏入成本降低,通過演算法的優化,可用更低的成本訓練出同等的訓練模型 ( 然而對算力的需求並沒有因此消失,如前面提及,未來更先進的模型仍必須投入更多算力及硬體設備 )
2. 開發出演算法優化公司不在美國,而是競爭對手中國,引發大家對於晶片管制其實無效的恐慌 ( 前面總結中國是通過優化的演算法成功,也因此反而更有晶片管制的必要,且實際上 OpenAI 執行長 Sam Altman 亦表示, DeepSeek-R1 zero 的創新非常貼近於過去 o1 開發過程中發現的點,只是 o1 選擇閉源開發 ),實際上美國的 AI 模型不論在硬體、軟體開發上皆仍然領先中國,但未來仍須注意中國在 AI 領域的競爭。)
而展望未來,DeepSeek 最大的影響為讓過去 AI 開發的閉源生態轉為開源,AI 開發速度將會加快、成本降低,有利於大型及中小 CSP 業者、以及加速導入全新 AI 推論模型及功能於 PC、手機當中,實現人人客製化的 AI agent。短期而言,CSP 業者的 Capex (資本支出) 還尚未看到薛減的跡象,未來須注意針對 AI 基礎設施的投資成長率是否趨緩,也預計市場將從注重 AI 硬體、晶片,更轉向於終端應用,並樂觀看待 AI 未來帶動人類社會生產力的提升。
以上內容僅供內部參考使用,不構成投資建議,未經同意不得轉傳、修改、販售,讀者須自行評估風險。


